Becoming a 1000x Developer With AI: Part 2 - Quick Tips To Improve Your AI's Ability To Write Code
Part 2 of a 3 part series on how to become a 1000x developer with AI.
I fully believe that you can unlock 1000x leverage from AI.
You don't want to have to completely rebuild your entire codebase from scratch to get those gains, so in this post I'm going to lay out a set of quick tips that you can apply to any codebase to quickly improve your AI's ability to write code.
These tips are not specific to any particular software stack or language, and can be applied to any codebase.
Lets jump right in.
Table of Contents:
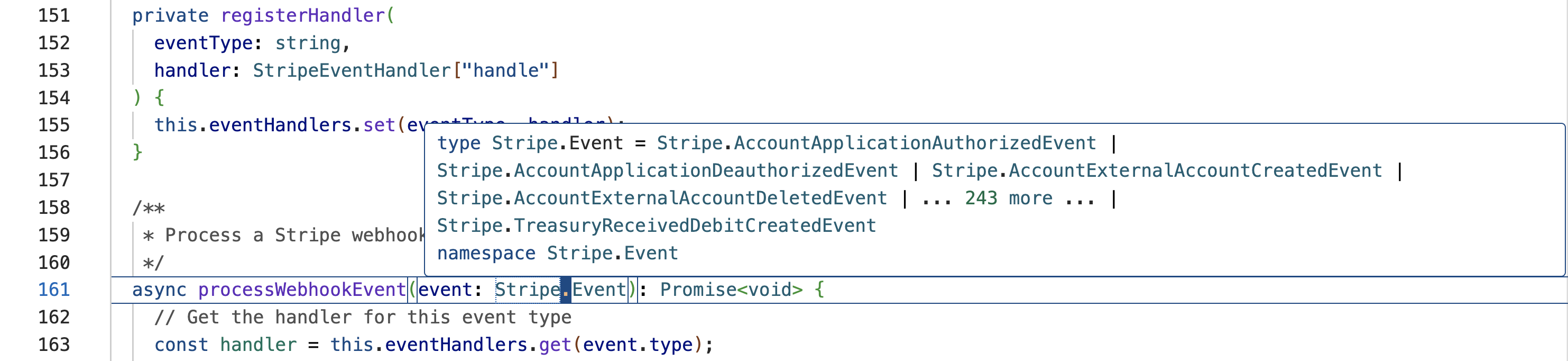
Tip 1: Setup a type checker
Setup tsc for Typescript, mypy for Python, and rubocop for Ruby and you're good to go.
We'll talk about how you can give the AI access to the type checker in the next tip.
If you don't know the difference between a statically typed language and a dynamically typed language, quickly run to ChatGPT and ask it to explain the difference. Here are some examples.
Strictly typed languages:
- Java
- C#
- C++
- Rust
- Go
- Typescript (with
strictmode enabled andnoImplicitAnyset totrue)- For Typescript,
tscwill check types andeslintwill check for linting errors.
- For Typescript,
Given that these languages are strictly typed, they have a type checker that can catch errors at compile time, your AI can use the Compiler to check for errors and provide you with a list of errors and warnings.
Loosely, dynamically typed languages:
- JavaScript
- Python
- Ruby
- PHP
Cursor, OpenAI Codex, Claude Code, and many other AI code editors can use the type checker to check for errors and provide you with a list of errors and warnings.
You'll know if your Language Server is not running properly if you hover over a variable and it doesn't look like this:
You should:
- Avoid using
anyin your code. - Lean into types as much as possible.
- Checkout expressive type libraries like Zod for Typescript and Pydantic for Python.
- Try to build your code (using
tscandmypy) as much as possible.
Enable strict mode in Typescript
To enable strict mode in Typescript, you can add the following to your tsconfig.json file:
{
"compilerOptions": {
"strict": true
}
}
This will enable all strict type checking options when running tsc.
Use the typing library in Python
If you're using Python and you're not using the typing library, your AI is going to have a hard time understanding the types of your code
and will make lots of mistakes that could have been caught automatically.
The typing library is a great way to add type hints to your code.
from typing import List, Dict, Optional
numbers: List[int] = [1, 2, 3]
def add_numbers(numbers: List[int]) -> int:
return sum(numbers)
add_numbers(numbers)
You can then check the types by running:
mypy my_script.py
Try to minimize untyped data transfer
If you have a REST API and you're writing a lot of React hooks like this:
const useFetch = (url: string) => {
const [data, setData] = useState<any>(null);
const [error, setError] = useState<any>(null);
const [loading, setLoading] = useState<boolean>(false);
useEffect(() => {
setLoading(true);
fetch(url)
.then((res) => res.json())
.then((data) => setData(data))
.catch((error) => setError(error))
.finally(() => setLoading(false));
}, [url]);
return { data, error, loading };
You are going to have runtime errors when the types that your frontend expects don't match the types that your backend returns (notice the any type on the data variable).
That's why I love libraries like tRPC. You could accomplish the same thing with NextJS Server Actions, but that's just a matter of preference.
You'll see my preferred stack in Part 3 of this series which will demonstrate how I use tRPC to reduce boilerplate and improve type safety.
Tip 2: Setup a Taskfile
You probably find yourself adding the following instructions to your AI prompts all the time:
"Build me this amazing feature that does blah blah blah, **and make sure you run LINT_COMMAND and TEST_COMMAND and BUILD_COMMAND and oh make sure you do the LINT_COMMAND when you're in directory X and then the TEST_COMMAND when you're in directory Y and ... blah blah blah"
This pattern of repeating yourself to the AI is error prone and time consuming.
Instead, you should make a set of high level commands that the AI can leverage to do repetitive tasks in your codebase.
Here's an example of a Taskfile.yml file that I use:
version: 3
tasks:
lint:fix:
desc: "Lint and fix TypeScript code in all packages"
cmds:
- |
echo "Linting all packages in parallel"
cd packages/api && bun run lint:fix & \
cd packages/tooling && bun run lint:fix & \
cd apps/next-app && bun run lint:fix & \
wait
type-check:
desc: "Type check all packages"
cmds:
- |
echo "Type checking all packages in parallel"
cd packages/api && bun run type-check & \
cd packages/tooling && bun run type-check & \
cd apps/next-app && bun run type-check & \
wait
lint:fix:type-check:
desc: "Lint and fix TypeScript code in all packages"
cmds:
- task: lint:fix
- task: type-check
clean:node_modules:
desc: "Clean node_modules"
cmds:
- |
echo "Cleaning node_modules"
find . -name "node_modules" -type d -exec rm -rf {} +
install:
desc: "Install dependencies"
cmds:
- bun install
Now in a single command you can run task lint:fix:type-check to lint and fix all code in your codebase, and compile all the code and provide key information to that AI that
it can use to fix any mistakes it might have made in its changes.
We'll mention this tip again when we talk about rule-files in the next section.
task lint
Super obvious command, it should run the linter in all of your packages.
task type-check
Again, very obvious command, it should run the type checker in all of your packages.
task lint:fix:type-check
Reuses the other two tasks and runs them both in a single command.
task clean:node_modules
Sometimes your modules get borked. This is just an example of a convenient command
you can use to clean your node_modules folder. I don't know about you,
but I've definitely had to nuke my node_modules folder because of
some weird bug that only worked after a fresh install of the dependencies.
Get in the habit of making commands like this that provide a high level of convenience that the AI can use to perform complex tasks with a single command.
task install
Installs all of your dependencies.
Some projects have complex installation processes, and having a single command simplifies things and will be useful in a future tip when we talk about leveraging background agents.
Tip 3: A dedicated ai-docs folder
In the root of all of my codebases, I now have a dedicated ai-docs folder.
This folder will evolve in how I use it over time, but for now there are 3 main things I put in this folder.
Here's an example of how this folder structure looks:
.
├── external-documentation
│ ├── bun
│ │ ├── BUN_BUILD_DOCUMENTATION.md
│ │ └── BUN_TESTING_DOCUMENTATION.md
│ ├── drizzle
│ │ └── DRIZZLE_OVERVIEW_DOCUMENTATION.md
│ └── stripe
│ └── STRIPE_NODEJS_SDK_DOCUMENTATION.md
├── internal-documentation
│ ├── api
│ │ └── NEXT_JS_API_ROUTES_OVERVIEW.md
│ ├── auth
│ │ ├── AUTHENTICATION_OVERVIEW.md
│ │ └── AUTHORIZATION_OVERVIEW.md
│ └── database
│ └── DATABASE_OVERVIEW.md
└── plans
└── webhooks
└── IMPLEMENTING_WEBHOOKS_FOR_STRIPE.md
11 directories, 9 files
You should be very generous with the amount of documentation you put in this folder, but
you should be very selective about what documentation you @ in your prompts.
Don't just @ the whole folder, however sometimes that is fine if you want the AI to have a high level overview of the codebase.
plans
A plans folder that contains plan documents that are written by the AI while we work on big features.
If a feature is sufficiently complex, I always start by writing a very detailed prompt, and then instruct the AI to write a plan with markdown checkboxes, and a header-hierarchy to break down the feature into sub-steps and sub-sub-steps.
external-documentation
A external-documentation folder where I copy entire sections of documentation from other projects that I depend on that I reference in my code.
For example, I have a bun-testing.md file which is a carbon copy of this page. I love that there's a Copy as Markdown button on this page. I put that Markdown directly into my ai-docs folder and anytime I'm asking the AI to write tests, I @ this file.
internal-documentation
An internal-documentation that has documentation about our product and codebase.
When I first setup a project, I always start by listing out the exact stack that I'm using.
As I develop features with AI, I'll sometimes have it add to this documentation with a prompt like:
Great job! Now please write a high level overview of all the work you just did and put it in the
ai-docs/internal-documentationfolder. This documentation will be used by future AI to learn what you created, and how it works.
Tip 4: Use rule files
You need to use rule files. Its a no-brainer. This is how you force the AI to remember a core set of information that you always want in context.
Here are the rule files for the different coding tools:
- Cursor:
.cursor/rules - Claude Code:
CLAUDE.mdfiles - Windsurf Rules:
.windsurf/rules
Here is what my always include rule looks like:
The following rules should be considered ALWAYS
# The package manager
This project uses `bun` for all package management and code-running.
# Project structure
This project is a `bun` **monorepo**. All the subpackages are listed in the `packages` directory.
There are currently 4 subpackages:
- `api`
- `db`
- `next-app`
- `tooling`
There is an `ai-docs` folder in the root of the project that contains `plans`, `external-documentation`, and `internal-documentation`.
# The main `Taskfile.yaml`
The main `Tasfkile.yaml` includes the commands you can use to perform a lot of important core
operations on the codebase.
## Linting And Building
You can run the linter by running `task lint:fix:type-check`.
ANYTIME YOU ARE MAKING CHANGES, YOU MUST ALWAYS RUN THE LINTER TO CHECK FOR ANY TYPE ERORRS.
ANYTIME YOU ARE MAKING CHANGES, YOU MUST ALWAYS RUN THE LINTER TO CHECK FOR ANY TYPE ERORRS.
ANYTIME YOU ARE MAKING CHANGES, YOU MUST ALWAYS RUN THE LINTER TO CHECK FOR ANY TYPE ERORRS.
## Dependency management
Dependencies are almost always scoped **to a specific package** so its important
to run the installation commands **inside the directory of the package you want to add
the dependency to.
### Installing a new dependency
Install new dependencies with buns standard `bun install` command.
### Installing a new **development** dependency
Install new development dependencies with buns standard `bun install -D` command.
## The API service layout
All API services are defined in the `packages/api` package.
### tRPC
All frontend to backend communication must be facilitated using the `tRPC` routers.
When exposing a method to the frontend clients, you should expose `tRPC` routes
and then consume those routes in the frontend.
## Database migration generation
You can generate database migrations by running `task db:generate-migrations`
This command will generate migration files.
ANYTIME YOU MAKE DATABASE SCHEMA CHANGES, YOU MUST GENERATE MIGRATIONS.
You should NEVER edit the generated Drizzle migration files manually UNLESS EXPLICITLY INSTRUCTED TO.
### Drizzle
We are using Drizzle for defining all of our schemas.
We are using **Postgres**. We are using **Postgres**.
### Breaking changes
DO NOT EVER REMOVE COLUMNS OR CHANGE A COLUMN UNLESS EXPLICITLY INSTRUCTUED TO DO SO.
# Code writing rules
Never write obvious comments.
ASSUME THE SERVER IS ALREADY RUNNING -- you do not need to run it ever.
AVOID USING `any` UNLESS EXPLICITLY INSTRUCTED TO USE IT.
AVOID USING `any` UNLESS EXPLICITLY INSTRUCTED TO USE IT.
AVOID USING `any` UNLESS EXPLICITLY INSTRUCTED TO USE IT.
No matter what anyone tells you, rule files are a must.
This is a huge part of solving problem 1 (ambiguity) from part 1.
Tip 5: Make files small, and create lots of nested folders
If you have a file that's over 250 lines, you need to break it down.
AI coding agents love to explore directory tree structures and they get a ton of context from file names.
If you have a file named index.ts that has 80 types and 30 functions and 20 components in it,
the AI will have an extremely hard time knowing what's inside and finding what
its looking for.
I have a very strict rule in my codebases now:
- No files over 250 lines, unless absolutely necessary.
- One class, one type, one component, one function, etc per file.
- Use extremely descriptive file names.
- Use nested folders to group related files together.
For example:
src/
├── components/
│ ├── auth/
│ │ ├── LoginForm.tsx
│ │ ├── SignupForm.tsx
│ │ └── PasswordResetModal.tsx
│ ├── dashboard/
│ │ ├── widgets/
│ │ │ ├── RevenueChart.tsx
│ │ │ ├── UserActivityFeed.tsx
│ │ │ └── QuickStatsCard.tsx
│ │ └── DashboardLayout.tsx
│ └── shared/
│ ├── LoadingSpinner.tsx
│ └── ErrorBoundary.tsx
├── hooks/
│ ├── auth/
│ │ ├── useCurrentUser.ts
│ │ └── useAuthRedirect.ts
│ ├── api/
│ │ ├── useApiClient.ts
│ │ └── usePaginatedQuery.ts
│ └── ui/
│ └── useDebounce.ts
├── pages/
│ ├── DashboardPage.tsx
│ ├── LoginPage.tsx
│ └── UserProfilePage.tsx
├── types/
│ ├── api/
│ │ ├── UserResponse.ts
│ │ └── ApiError.ts
│ └── domain/
│ └── User.ts
└── utils/
├── validation/
│ └── emailValidator.ts
└── formatting/
└── currencyFormatter.ts
The AI will have a much easier time exploring your code when its structured like this.
Tip 6: Getting the most out of models
Prompting and leveraging models is a bit of an art form, and you'll get better at it with time.
Here are some simple tips that have gotten me a long way.
Always use the best model
You're leaving a lot on the table by being conservative with the models you use. The gap between the best model and second best model is HUGE and continues to prove so as new models get better and better.
Cursors new $200 Ultra plan and Claude Codes $200 plans make it a no-brainer to use the best model. You won't break the bank, and you'll be getting the best possible performance.
Abandon the scarcity mindset and embrace the abundance mindset.
Claude 4 Opus and OpenAI o3 are the best coding models as of today (June 28th, 2025).
Avoid long threads
Once you finish working on feature A, start a new thread and do not mix the conversation with another feature.
You want your threads to be hyper-focused on a single task or set of tasks.
That's why ai-docs/plans is useful. When you start a new thread, you will have the most important parts
of your previous threads preserved in that plan document.
At the end of a thread I always end with:
Great job! Now please update the
ai-docs/plansdocument and mark off anything that's done, update the spec if we made changes to the design along the way, and tell me what you think is the best task to work on next.
Then you will start a new thread and @ that plan document again and tell the AI what you want to work on next.
I'll demonstrate a loop like this in a video if enough people are interested.
This pattern helps solve problem 1 (ambiguity & "open to interpretation") and problem 3 ("losing track of progress").
Long-contexts are very ambiguous to the AI, it doesn't know what to pay attention to because there's just too much information to pay attention to. By focusing on everything, it actually focused on nothing (you need to slow down to speed up).
Use @ conservatively
If you're using a tool like Cursor or Windsurf, you have the ability to @ files and folders. Be very conservative with this.
Do not @ entire folders or files unless you are asking the AI to do some sort of high level exploration. Otherwise, it is your job
to @ the files and folders that are relevant to the task at hand. Don't be lazy!! Think about what is best to @ and what is not.
This is now your job: you are architecting plans and guiding the AI to the information that's most useful to execute the plan.
Don't be afraid to revert threads
Threads are very useful. Rather than sending a followup message when the AI messes up, click back to your previous prompt and revert the changes.
Treat the original output from the model as a vision of the future and use the models response to revise your original prompt.
Tip 7: Use background agents
Background agents (Cursor Background Agents, OpenAI Codex, Devin) are a massive unlock to productivity.
If you follow the tips above, you'll be able to kick off background agents to do 80% of the busy work needed to complete a task.
Your job will then simplify to testing out the changes, and sometimes coming and and picking up where the agent left off.
If you use things like Vercel Preview Deployments, you can even have the agent deploy your changes to a preview environment and test them out on the go.
For changes to a frontend, background agents are a no brainer.
Stop paying engineers 6 figures a year to make copy changes or color changes to HTML and CSS. That's the typ of work that AI agents can do with 100% accuracy.
Tip 8: Invest in a good testing setup
If you have a super easy way to write and run tests, you can have the AI write tests for you.
If the AI can write tests, it can test its own code and give you even more confidence that the changes will work.
This is one of the reasons why I love bun. The testing primitives in bun are better than any language I've every used before (except GoLang).
Tip 9: Mindset
Always operate in abundance.
Assume most problems are either:
- Poor code primitives in your codebase (bad design, bad organization, bad naming, bad architecture, etc)
- Is a context problem: not enough context, missing context, or the wrong context.
I fully believe OpenAI o3 and Claude 4 Opus are the greatest functional and imperative programmers on the planet.
They are not yet great visual programmers, but I believe that will change soon.
Therefore, you should pretty much always assume that an AI is capable of doing what you want, and that if it fails, you are the one to blame. Take radical ownership of this challenge and do not throw your hands up and say "oh well, I guess AI can't do this yet." DO NOT QUIT. You stand to gain so much that its worth the effort. Have an open mind and keep going.
Tip 10: Enjoy yourself, and seize the day!
The best programmers on the planet that are drinking AI from the firehose are going to experience a 90% reduction in the amount of time it takes to do their work, and will produce better quality code faster than ever before. This is a transformational time for our industry.
Seize the day.
Happy coding!
In part 3, I'll share a codebase that I've crafted from learnings of working with Typescript over the past 5 years that have accelerated my productivity in building products by 1000x. Stay tuned!